


| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 실시간 스트리밍 데이터
- 추적 데이터 마이닝 파이프라인
- s3
- 마운트
- Terraform
- 분산추적
- jack 문법
- SpanId
- nandtotetris
- APM 만들기
- ec2
- 컴퓨터 아키텍쳐
- vm머신
- 피벗 추적
- 구문 분석
- apm
- 핵심 데이터 모델링
- 메모리 세그먼트
- 시간 윈도우
- MySQL
- 리눅스
- 도커
- 텀블링 윈도우
- vm번역기
- InnoDB
- OTEL
- 스트리밍 아키텍쳐
- 스택머신
- 밑바닥부터 만드는 컴퓨팅 시스템
- 스트리밍 데이터 아키텍쳐
- Today
- Total
이것이 점프 투 공작소
프로메테우스의 메트릭-Metric에 대해 알아보자 본문
Metric이란?
시스템의 서비스 및 성능, 상태를 모니터링하는 지표입니다.
프로메테우스는 메트릭을 수집하고 저장하는 모니터링 시스템입니다.
메트릭은 아래와 같이 익스포터의 /metrics API에서 이름(Name), 레이블(Labels), 값(Value)를 통해 정의됩니다.
메트릭의 이름에는 -을 쓸수없고 숫자로 시작 할 수 없습니다.
flask_http_request_total{method="GET",status="200"} 6.0
# 메트릭이름{레이블} 값메트릭을 수집할 서버들은 /metrics 주소로 프로메테우스로 수집할 메트릭들을 노출하는데
프로메테우스에서 curl <IP>:<PORT>/metrics | promtool check-metrics 라는 명령어로 노출된 메트릭들이 유효한지 확인 할 수 있습니다.
어떻게 메트릭을 수집해야하는가?
1. 서비스
사용자나 다른 서비스 이용자가 응답을 기다리는 서비스의 경우, 요청비율(Rate), 대기시간(Duration), 오류비율(Error Rate) 3가지 지표 RED메소드를 기준으로 메트릭을 수집하는게 좋습니다.
2. 오프라인 작업
사용자가 응답을 받지않는 로그 처리 시스템같은 오프라인 작업에서는 활용도(Utilization), 포화도(Saturation), 오류(Error) USE메소드를 기준으로 메트릭을 수집하는게 좋습니다.
활용도는 서비스가 얼마나 충분한지, 포화도는 대기중인 작업의 양을 의미합니다.
3. 일괄처리 작업 (배치작업)
배치와 같은 일괄처리 작업에서는 PUSH 게이트웨이 기법이 주로 사용됩니다.
프로메테우스의 메트릭(Metric) 종류
카운터 (Counter)
메트릭을 추적하고 카운트하는데 사용하는 지표 유형입니다.
API의 요청횟수나 발생한 횟수를 추적하는데 사용되며, 0부터 시작하여 오직 증가하는 값만을 가질 수 있습니다.
어플리케이션 레벨에서 exception 발생시 수집하는 메트릭을 만들어 예외가 발생한 메트릭을 수집할수도 있습니다.
Counter 타입에 rate 함수를 적용하면 Gauge 타입으로 변환된다는 되며, 추가로 카운터 메트릭은 _total 로 끝나는 규칙을 가지고 있습니다.
FLASK 예제 코드
hello_worlds_total 이란 이름으로 카운터 메트릭을 정의하였습니다.

Counter에 PromQL함수
1. sum()
여러 카운터 메트릭을 합치거나 특정 레이블에 대해 그룹화된 메트릭의 합계를 반환합니다.
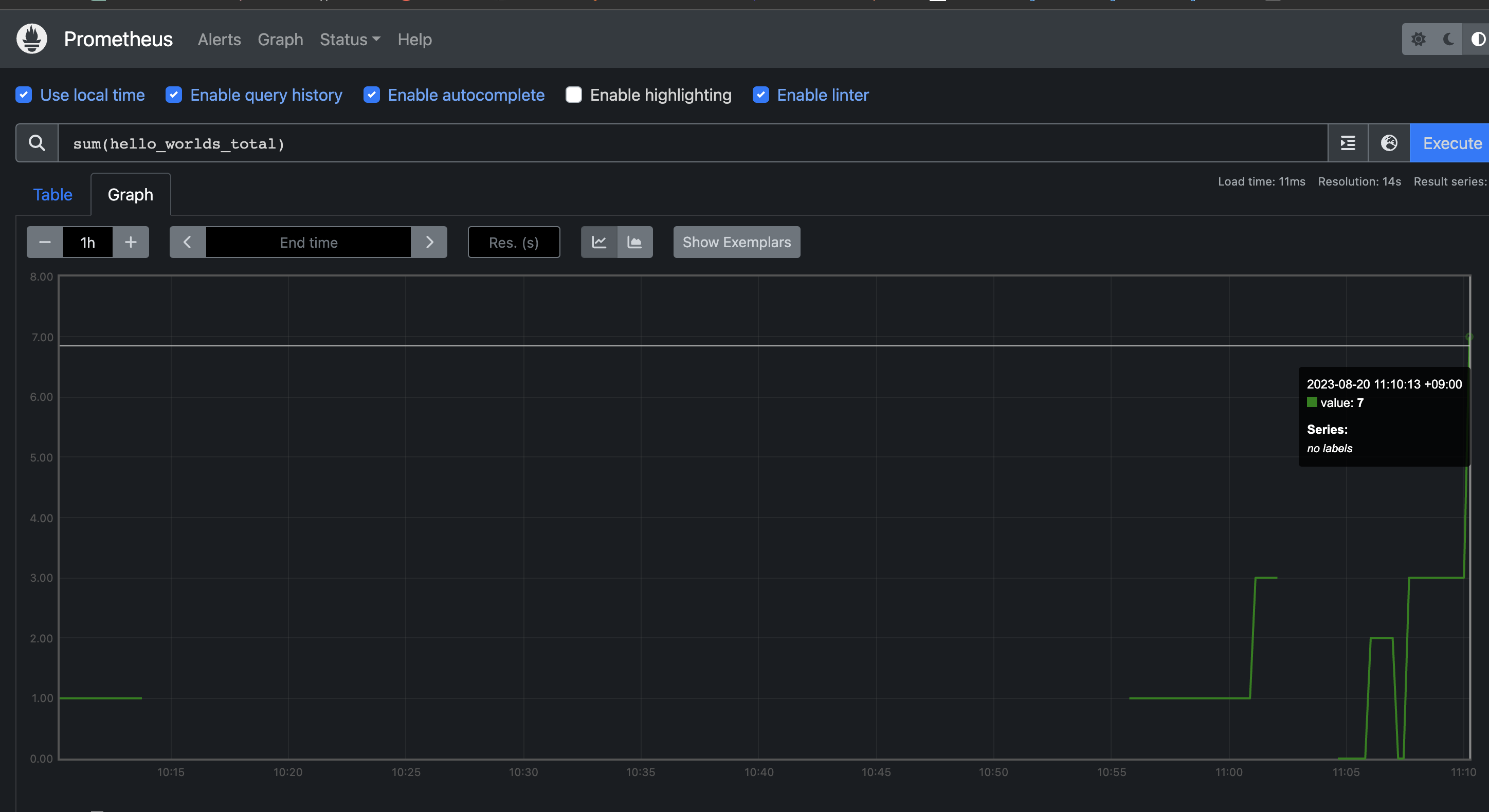
2. rate(메트릭[시간])
메트릭의 변화율을 계산합니다.
시간단위를 파라미터로 넣어 해당 간격동안 메트릭이 얼마나 변화했는지 확인 할 수 있습니다.

3. increase(메트릭[시간])
메트릭의 증가량을 계산합니다.
rate()와 동일한 인자를 가집니다.

4. topk(숫자,메트릭), bottomk(숫자,메트릭)
Counter 메트릭의 상위, 하위 값을 선택합니다.
가장 많이 발생한 항목을 찾는데 사용됩니다.
파라미터의 숫자를 통해 가져올 갯수를 정의합니다.
2. 게이지 (Gauge)
증가 및 감소가 가능한 값을 측정하는데 사용되는 메트릭입니다.
inc(), dec(), set() 함수를 통해 메트릭을 조정 가능합니다.
카운터가 얼마나 빨리 증가하는가에 초점을 둔 메트릭이라면 게이지는 실제 현재 값에 중심을 두고 관측합니다.
일반적으로 현재 연결된 커넥션수, 메모리 사용량, 디스크 공간 등 실시간 형태의 값을 추적할 떄 사용됩니다.
코드 예시
hello_worlds_inprogress로 해당 API에서 연결중인 커넥션 수를
hello_world_last_time_seconds로 해당 API의 마지막 호출 시간을 수집합니다.
PromQL에서 time() - hello_world_last_time_seconds 을 통해 API가 마지막 요청 후 얼마나 많은 시간이 지났는지도 확인 할 수 있습니다.
추가로 프로메테우스의 설정을 변경후 리로드 하고싶으면 아래 API를 호출하면됩니다.
curl -X POST http://프로메테우스IP:<포트>/-/reload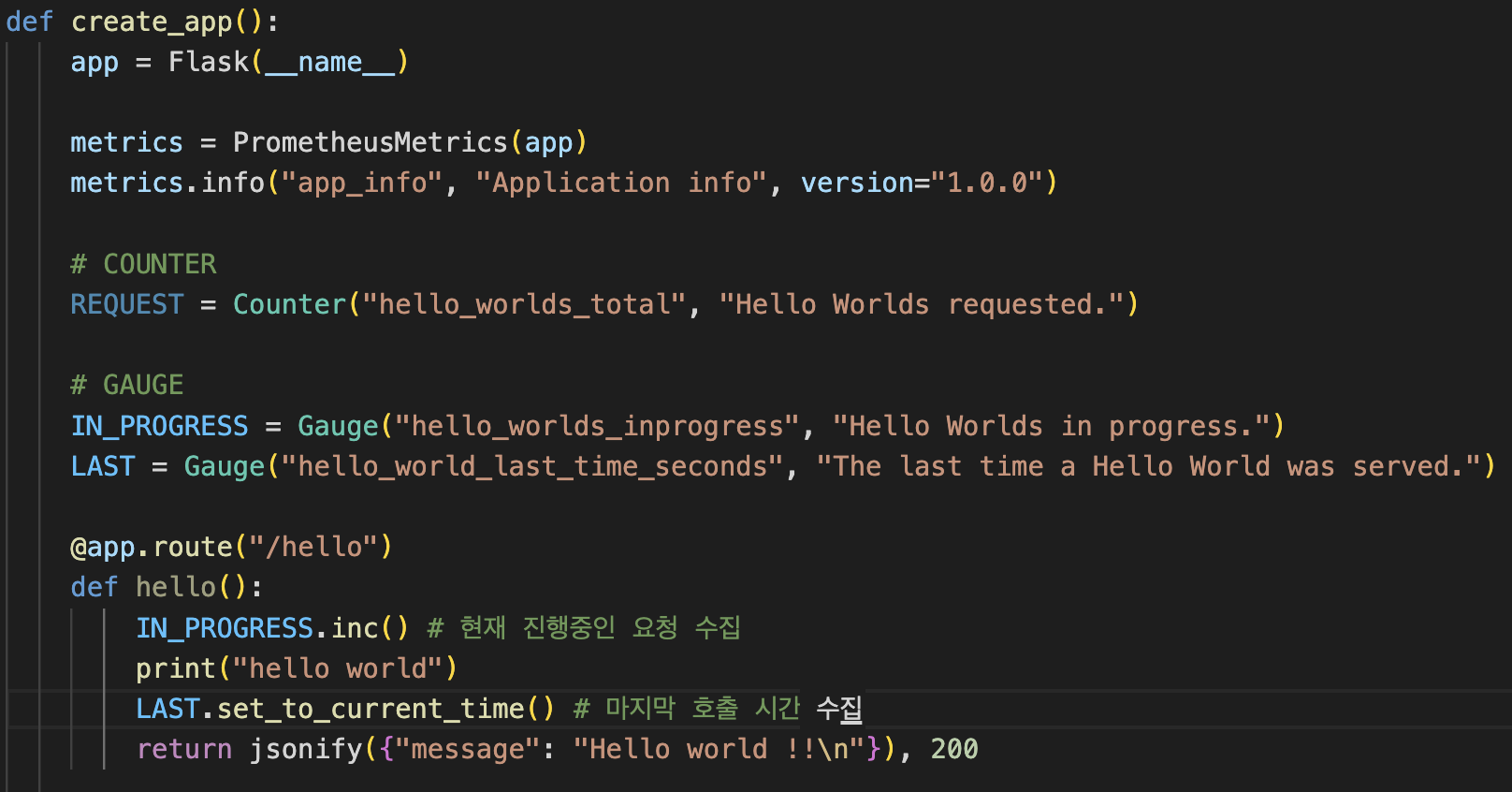
1. rate(메트릭[시간])
카운터의 PromQL과 동일하게 메트릭의 변화율을 계산합니다.
시간단위를 파라미터로 넣어 해당 간격동안 메트릭이 얼마나 변화했는지 확인 할 수 있습니다.
2. increase(메트릭[시간])
카운터의 PromQL과 동일하게 메트릭의 증가량을 계산합니다.
rate()와 동일한 인자를 가집니다.
3.changes(메트릭[시간])
시게열 백터의 변화 포인트 수를 반환합니다.
게이지 메트릭이 값이 증가하고 감소한 횟수를 계산시 사용합니다.
4.reset(메트릭[시간])
게이지 메트릭 값이 재설정된 횟수를 반환합니다.
3. 서머리(Summary)
분포를 요약하여 제공하는 메트릭 타입니다.
백엔드에서 지연시간이나 처리시간은 중요한 지표입니다.
프로메테우스에서는 Summary 를 이용하여 지연시간, 처리시간과 같은 연속형 값을 다룰때 사용합니다.
분포의 합계, 카운트, 최소값 및 분위수를 계산합니다.
코드예시
observe메소드를 통해 metrics에 처리시간에 대한 값을 전달해줍니다.
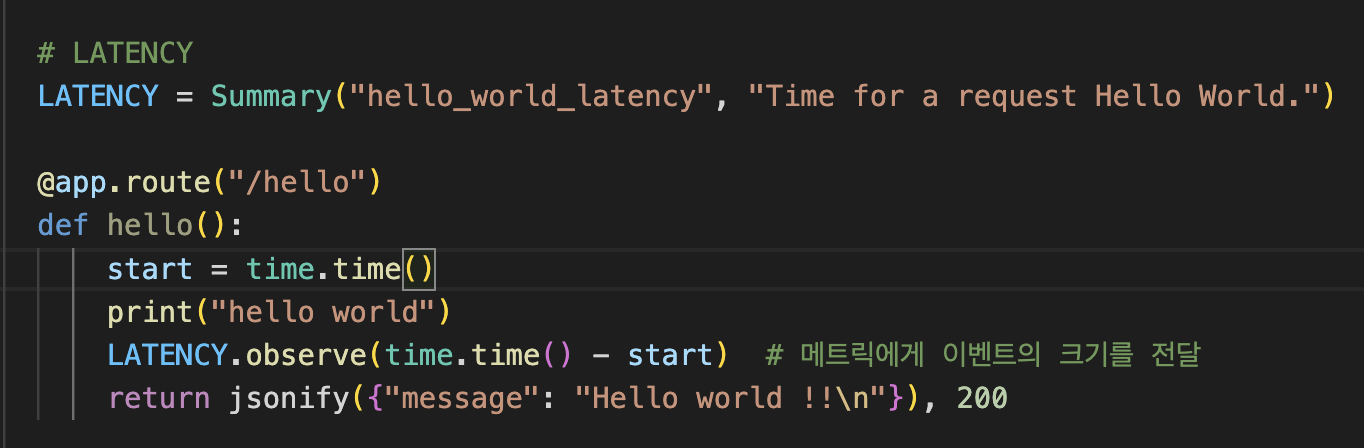
Summary 메트릭을 등록하면 /metrics에 hello_world_latenct_count(observe의 호출갯수), hello_world_latenct_sum( observe에 전달된 값의 합) 두개의 메트릭이 생성되고 Summary는 두 메트릭을 참조합니다.

두 메트릭을 조합하며 Summary를 구할 수 있습니다.
rate(hello_world_latency_sum[1m])/rate(hello_world_latency_count[1m])
히스토그램 (Histogram)
연속적인 데이터 값의 분포를 측정합니다.
Summary는 평균 대기시간 같은 값들을 측정하고 Histogram을 통해 분위수를 측정 할 수 있습니다.
주어진 범위 내에서 데이터를 버킷으로 그룹화 하고 각 버킷의 데이터를 집계합니다.
사용자 경험에 대해 추론할 때 유용합니다.
히스토그램은 연속적인 데이터 범위를 가지는 측정값들을 버킷(buckets)으로 나누고,
각 버킷 안에 데이터를 집계하여 분포를 나누게됩니다.
어플리케이션 코드 내에서 Histogram을 생성할때 버킷의 범위를 지정 하여 메트릭을 생성 할 수도 있습니다.
게측방식은 Summary의 계측방식과 동일합니다.


'모니터링' 카테고리의 다른 글
| 프로메테우스의 집계 연산자 (0) | 2023.08.28 |
|---|---|
| 프로메테우스 PUSHGATEWAY에 대해 알아보자 (0) | 2023.08.20 |

