


| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 밑바닥부터 만드는 컴퓨팅 시스템
- 실시간 스트리밍 데이터
- vm번역기
- jack 문법
- APM 만들기
- vm머신
- ec2
- 분산추적
- apm
- 도커
- 추적 데이터 마이닝 파이프라인
- 텀블링 윈도우
- 컴퓨터 아키텍쳐
- 스트리밍 데이터 아키텍쳐
- MySQL
- InnoDB
- nandtotetris
- OTEL
- 리눅스
- 스택머신
- 피벗 추적
- 핵심 데이터 모델링
- 마운트
- 구문 분석
- s3
- 스트리밍 아키텍쳐
- SpanId
- 메모리 세그먼트
- 시간 윈도우
- Terraform
- Today
- Total
이것이 점프 투 공작소
NandToTetris : 컴파일러 1: 구문 분석-밑바닥부터 만드는 컴퓨팅 시스템 본문

컴파일 과정은 크게 둘로 나뉩니다.
먼저 프로그램의 구문(syntax)를 이해하고, 그 구문을 통해 프로그램의 의미(semantics)를 찾습니다.
예를 들어 프로그램 코드를 분석(parsing)해서 배열을 선언하거나 객체를 조작하려고 한다는 사실을 파악했다고 하면,
그 언어의 구문을 이용해 코드를 다시 표현 할 수 있습니다. 이를 구문 분석(syntac analysis)라고 부릅니다.
구문 분석기는 tokenizer와 parser로 나뉩니다.
두번째 과정인 코드 생성(code generation)은 다음장에서 다룹니다.
핵 플랫폼에서는 구문 분석기가 소스코드의 구문 구조를 반영하는 xml 마크업 파일을 출력하도록 하는 것 입니다.
구문 분석기에서 만든 xml 파일을 code generator가 사용합니다.
Tokenizer

구문 분석기에서 입력된 문자들을 토큰이라는 언어의 기본 요소들로 분류하는 tokennizing 단계를 처리하고
토큰들을 의미가 있고 구조화된 명령문들로 분석하는 단계입니다.
어휘 분석
Tokenizer에 입력이 들어오면 먼저 들어온 문자들을 어휘(lexicon)에 맞게 분류합니다.

프로그래밍 언어의 명세에는 언어가 인식하는 token 또는 단어의 유형이 존재합니다.
우리의 jack 언어는 다섯 가지 유형으로 분류됩니다.
이런 유형으로 정의되는 토큰들을 모아서 언어의 어휘 (lexicon)이라 부릅니다.
- 키워드(class, while)
- 기호(+,<)
- 정수형 상수(17,314)
- 문자열 상수("FAQ", "Frequently Asked Questions")
- 식별자(변수, 클래스, 서브 루틴의 이름을 뜻하는 텍스트 레이블)
가장 가장 단순한 형태의 컴퓨터 프로그램은 텍스트 파일에 저장된 문자열입니다.
구문 분석의 첫 단계는 공백, 주석을 무시하고 문자들을 언어 어휘로서 정의된 토큰으로 분류하는 것 입니다.
이 단계는 어휘 분석 analysis, 스캐닝 scanning, 토큰화 tokenizing로 불리며 모두 같은 뜻입니다.
아래 그림에서 jack언어의 어휘(lexcion)들과 일반적인 코드들이 어떻게 처리되는지 볼 수 있습니다.

문법
토큰 또는 단어스트림으로 인풋으로 주어진 텍스트를 처리하고 나면, 그 단어들을 유효한 문장으로 묶을 수 있습니다.
문법적으로 유효한 문장을 만들기 위한 문법은 메타 언어 meta-language (언어를 기술하는 언어)로 작성됩니다.

# if조건문 문법
# 규칙 이름 : 문법
ifStatement: 'if' '(' expression ')' '{' statements '}'- Jack의 if문은 'if' 키워드로 시작해야 함
- 다음에 '(' (여는 괄호) expression (조건식, 예: x > 5) ')' (닫는 괄호)
- '{' (여는 중괄호) statements (실행할 코드)'}' (닫는 중괄호)
문법은 3가지 요소로 순서대로 구성되는데
단말 terminal, 비단말 non-terminal, 한정자 quailifier 입니다.
- 단말 Terminal : 토큰, 오른쪽이 상수로만 구성된 규칙
- 비단말 Non-Terminal : 다른 규칙의 이름과 상수로 구성된 규칙
- 한정자 Quailifier : |, *, ?, (, )의 다섯가지 기호
한정자 quailifier 는 특정요소가 몇번 등장 할 수 있는지 나타내는 기호입니다.
예를들어
- statements: statement* 는 let y = 10; if (x > y) { let x = y; } 이런식으로 여러개의 statement를 허용한다는 의미입니다.
- statement: letStatement | ifStatement | whileStatement → statement는 let, if, while 중 하나만 선택 가능하다는 의미가 됩니다.
- expression: term (op term)? → term은 필수, (op term)은 0개 또는 1개만 허용된다는 의미입니다.
아래 표에서
단말 Terminal은 아래 그림에서 if, let 처럼 굵게 처리된 단어들입니다.
비단말 Non-Terminal은 기울임꼴로 적혀있는 단어들입니다.

파싱 트리
토큰화된 코드를 문법적 구조로 변환하는 과정에서 생성하는 트리입니다. (xml로 변환)
파싱트리를 통해 jack 프로그램이 올바른 구문을 따르는지 확인하고, 이후 코드 생성 단계에서 이를 활용합니다.
핵 플랫폼에서는 파싱 트리 구조를 반영하는 마크업 형식의 xml파일을 파서의 출력이 되도록 했습니다.
아래 그림을 보면 문법을 기준으로 구문들을 분리하고, 들어가서 또 분리하기를 반복하며 (재귀)
모든 토큰들을 분류하여 트리구조로 만듭니다.

아래 그림은 whileStatement 서브루틴이 실행되면 어떤 결과로 파싱트리가 만들어지는지 보여줍니다.

파서 Parser

파서는 토큰을 순서대로 입력받아 대응하는 파싱 트리를 xml파일로 생성합니다.
파싱 트리를 구성하는 알고리즘이 몇 가지 있는데, 그중 재귀 하향 파싱 recursive descent parsing 방법을 사용해 언어 문법에 사용된 중첩 구조를 이용해 토큰화된 입력을 재귀적으로 분석합니다.
파싱 트리는 들어온 구문들을 토큰단위로 분리하기 위해 계속해서 재귀적으로 구문을 처리합니다.
whileStatement는 compileWhileState()로 처리되는데
저 compileWhileState()메소드 안에는 아래 그림처럼 재귀적으로 각 구문들을 처리하는 함수들이 필요합니다.

위에 whileStatement는 간단하지만 클래스 static 변수와 인스턴스 field 변수를 정의하는 규칙에서는 더 복잡해집니다.
아래 그림은 클래스 static 변수와 인스턴스 field 변수를 정의하는 규칙입니다.

맨 앞에 static, field 두가지 토큰이 다 시용 가능하고, 클래스의 static 변수와 인스턴스 필드 변수 선언은 여러 변수를 한 번에 선언할 수 있습니다.
compileClassVarDec() 함수는 입력에 있는 여러 변수 선언을 처리하기 위해 반복문을 사용합니다.
이 반복문은 하나의 변수 선언을 처리한 후, 또 다른 변수 선언이 있을 경우 다시 반복하여 처리하는 방식으로 동작합니다.
LL 문법

컴파일러는 LL 문법을 사용하여 코드를 파싱합니다.
LL 문법이란, 왼쪽에서 오른쪽으로 읽으며, 왼쪽(L) 파생을 사용하는 문법을 의미합니다.
- LL(1): 첫 번째 토큰만 보고 어떤 문법을 적용할지 결정할 수 있는 경우
- LL(2): 첫 번째 토큰만으로 구별할 수 없어서, 두 번째 토큰까지 확인해야 하는 경우
앞서 var, let, while을 사용하는게 컴파일러를 만들 때 유리하다고 언급되었는데 여기서 그 이유가 나옵니다.
var, let, while 같은 키워드를 앞에 두면 컴파일러는 첫 번째 토큰을 읽는 순간 바로 어떤 구문인지 알 수 있기 때문에
백트래킹없이 빠르고 효율적인 파싱이 가능해집니다.
첫번째 토큰으로 어느 문법 규칙을 봐야할지 판단할수 있으면 LL(1),
첫번째 토큰으로 모호하면 LL(2)로 두번째 토큰까지 확인합니다.
이렇게 하면, 파서가 첫 번째 토큰만 보고 어떤 규칙을 따라야 하는지 결정할 수 있어 백트래킹 없이도 효율적인 파싱이 가능합니다
Jack문법 정리
jack 언어의 문법은 아래와 같은 문법을 따르며
구문 분석기도 아래와 동일한 규칙을 사용해 파싱합니다.

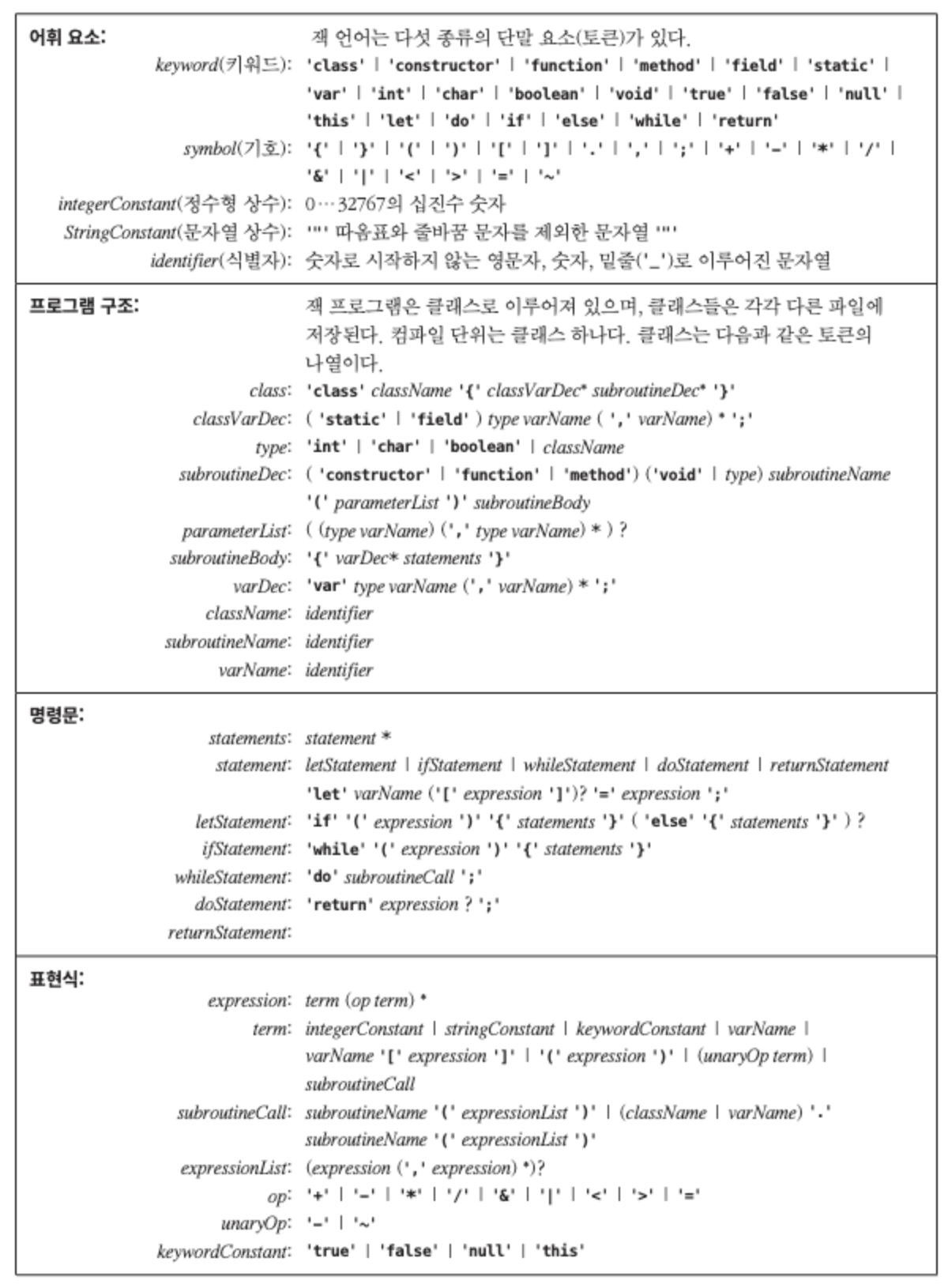
구문 분석기 구현목록
핵 플랫폼에서는 구문 분석기를 만들기 위해서는 아래의 3가지 모듈을 구현하는것을 제안합니다.
다음장에서 기호테이블과 vm코드 생성기를 추가로 만들면 컴파일러가 완성됩니다.
JackAnalyzer : 다른 모듈을 불러오고 설정하는 메인 프로그램
JackTokenizer : 토큰화 모듈
ComplicationEngine : 재귀 하향식 파서 (추후 컴파일 엔진 역할도 함)
JackTokenizer
입력 스트림의 주석과 공백을 제거하고 한번에 하나의 토큰에 접근하도록 만들어줍니다.
아래는 JackTokenizer의 함수들입니다.

ComplicationEngine
구문 분석기에서 컴파일 엔진은 JackTokenizer를 통해 들어온 입력코드를 xml태그로 변환해 출력합니다.
출력은 xxx를 컴파일하는 compilexxx루틴들이 생성합니다.
대응되는 compilexxx이 없는 문법 규칙들 (type, className, subroutineName, varName, statement, subroutineCall 등) 은
구조화를 위해 따로 함수(compileXXX())로 만들지 않습니다.
대신, 해당 문법 규칙이 필요한 다른 compileXXX() 함수 안에서 직접 처리합니다.
대부분 LL(1)으로 처리되지만 term, subroutineCall과 같은 경우를 처리할 때에는 LL(2)가 반드시 필요하게됩니다.
subroutineCall 예시 : bar(x + 2)
term 예시 : (x + 1), arr[2]

JackAnalyzer

JackTokenizer와 ComplicationEngine를 통해 전체 구문분석을 진행하는 모듈입니다.
Xxx.jack 파일마다 JackAnalyzer 모듈은 아래와 같은 작업을 합니다.
(Jack 파일을 컴파일하려면 가장 먼저 compileClass가 실행되어야합니다.)
1. Xxx.jack 파일마다 JackTokenizer를 생성합니다.
2. XXX.xml이라는 출력파일을 생성합니다.
3. JackTokenizer와 ComplicationEngine를 사용하여 입력파일을 파싱하고 파싱된 코드를 출력파일에 기록합니다.
'NandToTetris' 카테고리의 다른 글
| NandToTetris : 운영체제-밑바닥부터 만드는 컴퓨팅 시스템 (0) | 2025.03.16 |
|---|---|
| NandToTetris : 컴파일러 2: 코드 생성-밑바닥부터 만드는 컴퓨팅 시스템 (0) | 2025.03.10 |
| NandToTetris : 고수준 언어 Jack-밑바닥부터 만드는 컴퓨팅 시스템 (1) | 2025.03.07 |
| NandToTetris : 가상머신2-제어-밑바닥부터 만드는 컴퓨팅 시스템 (0) | 2025.02.26 |
| NandToTetris : 가상머신1-프로세싱-밑바닥부터 만드는 컴퓨팅 시스템 (0) | 2025.02.19 |



